 mzPeak
mzPeakThe modern
mass spectrometry
data format
Compact, fast, and cloud-native — a Parquet-in-ZIP successor to mzML. Losslessly smaller, and randomly addressable straight over HTTP.

Built for today's data volumes
Everything mzML can describe, stored in a layout built for terabyte archives, cloud workflows, and AI pipelines.
Compact
Columnar Parquet compression makes a file typically a fraction of the equivalent mzML and between 30–100% of vendor formats — lossless.
0.18–0.57× · losslessCloud-native
Designed for S3-compatible object storage and data lakes. Random access fetches only the bytes you need — so you pay for less egress and move less data.
S3 · data lakeFast
Open a 3 GB file and read any spectrum near-instantly — under 1s locally, under 2s from remote S3. Ion images and XICs extract in seconds, in the browser.
3 GB in < 2sAI-ready
Built on Apache Parquet, the native format of modern AI/ML stacks. Read directly by pandas, Polars, Spark & Arrow — no custom parser — and stream columns straight from the data lake into training.
pandas · Polars · SparkOpen & interoperable
ZIP-of-Parquet is language-independent, and the semantics are anchored in the PSI-MS controlled vocabulary — with a versioned conformance profile and validator.
PSI-MS · validatedExtensible
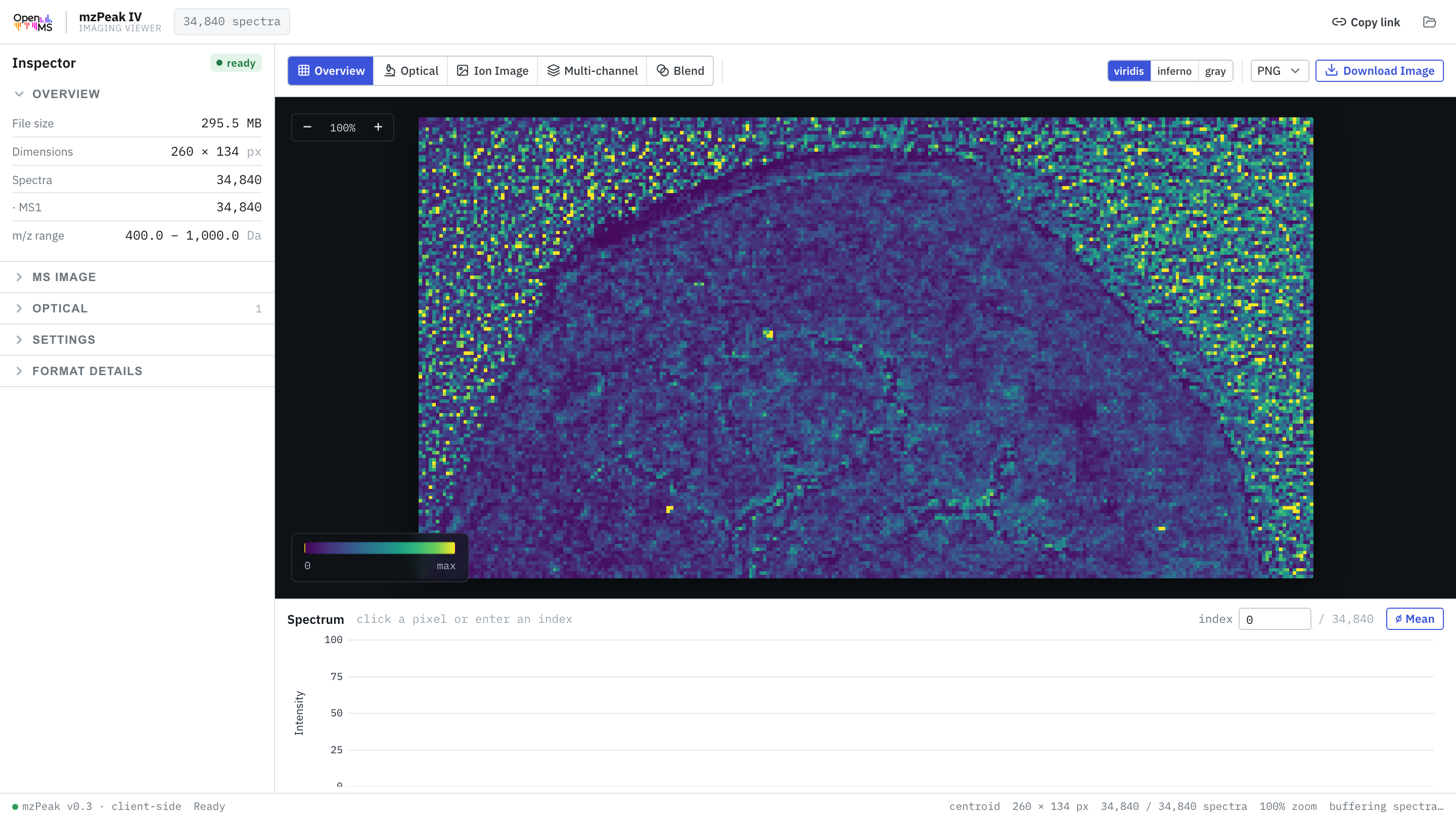
First-class extensions for MS imaging (per-pixel spatial data) and sample metadata (SDRF / ISA) — the format grows by extension, never by incompatible forks.
MSI · SDRF / ISASecure
Parquet's modular encryption can protect individual columns or files with AES-GCM, leaving the rest of the archive readable. How sensitive index fields and post-quantum-safe schemes are handled is an open design question.
AES-GCM · per-columnBackwards-compatible
Metadata aligns with the HUPO-PSI mzML standard, so lossless mzML ↔ mzPeak conversion is tested on hundreds of datasets — with ProteoWizard support in preparation.
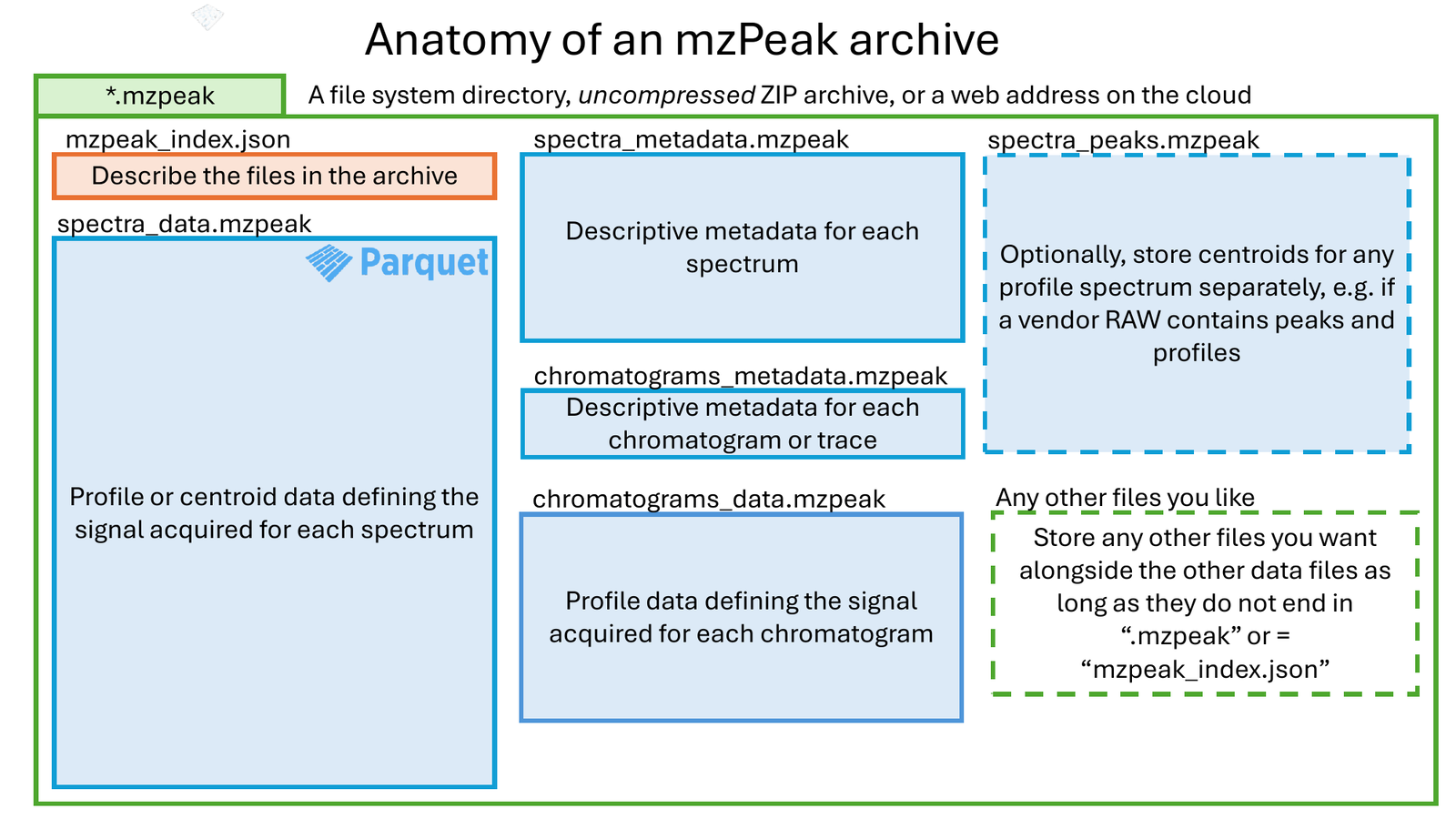
mzML ↔ mzPeakA ZIP archive of Parquet tables, plus a small JSON index
Columnar, compressed, randomly addressable, and self-describing. Everything a reader needs to find one spectrum — without parsing the whole run — lives in the manifest.
New kinds of data attach through documented entity-type and data-kind mechanisms, so optical images, sample metadata, and provenance all ride along in the same container.
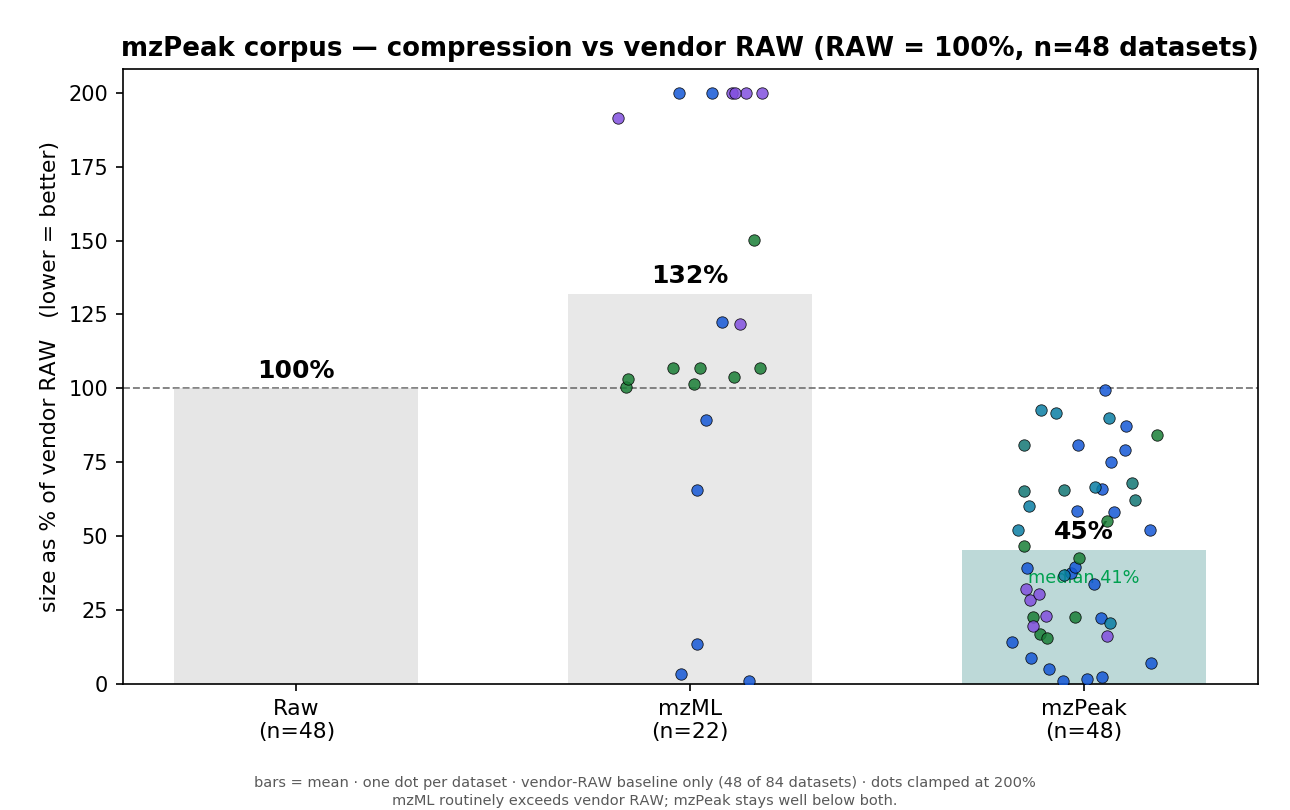
A fraction of the size — losslessly
Real datasets across seven instrument classes. Each bar is the mzPeak file size relative to the equivalent mzML — on average about 0.37×, and as small as 0.18×.
Everything around mzPeak is open source
A specification, reference readers and writers, converters, a conformance validator, and in-browser viewers. Browse the Build hub →
The canonical format spec — JSON Schemas, controlled-vocabulary rules, and prose.
The mzpeak_prototyping reader/writer — direct conversion from Thermo RAW and Bruker .TDF.
Convert imzML / mzML to mzPeak and back, with full round-trip verification.
A language-independent, profile-driven conformance validator. mzpeak-validate file.mzpeak
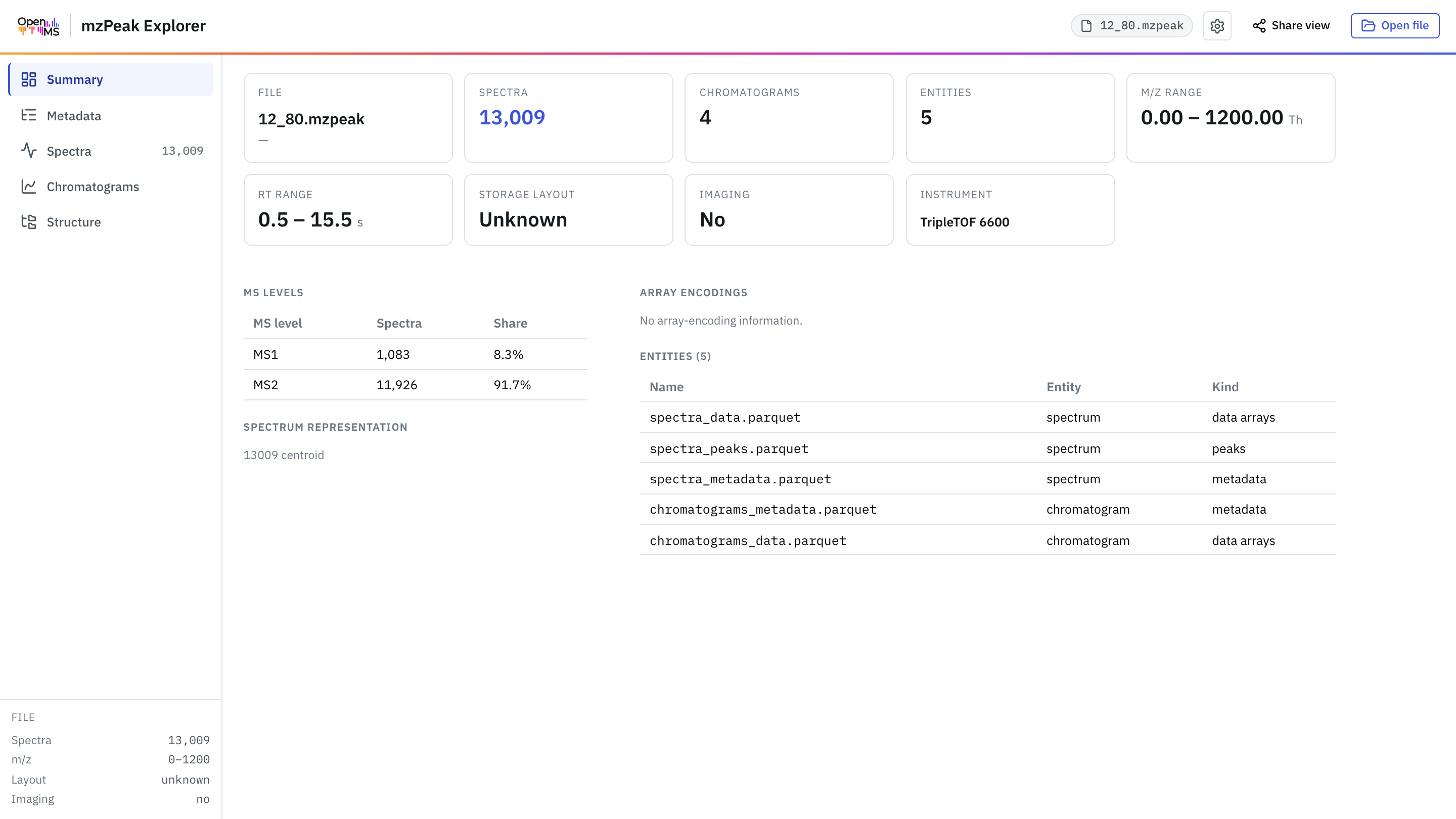
Open any .mzpeak directly in your browser, streamed over HTTP — no upload, no backend. Spectra and chromatograms for LC-/GC-MS, ion images for MS-imaging (MSI).
Build on the format
mzPeak is developed as an open community effort under HUPO-PSI. The specification is language-independent — start from the spec, validate against the conformance profile, and ship.